1. Top Tips Optimize Spring-boot Performance
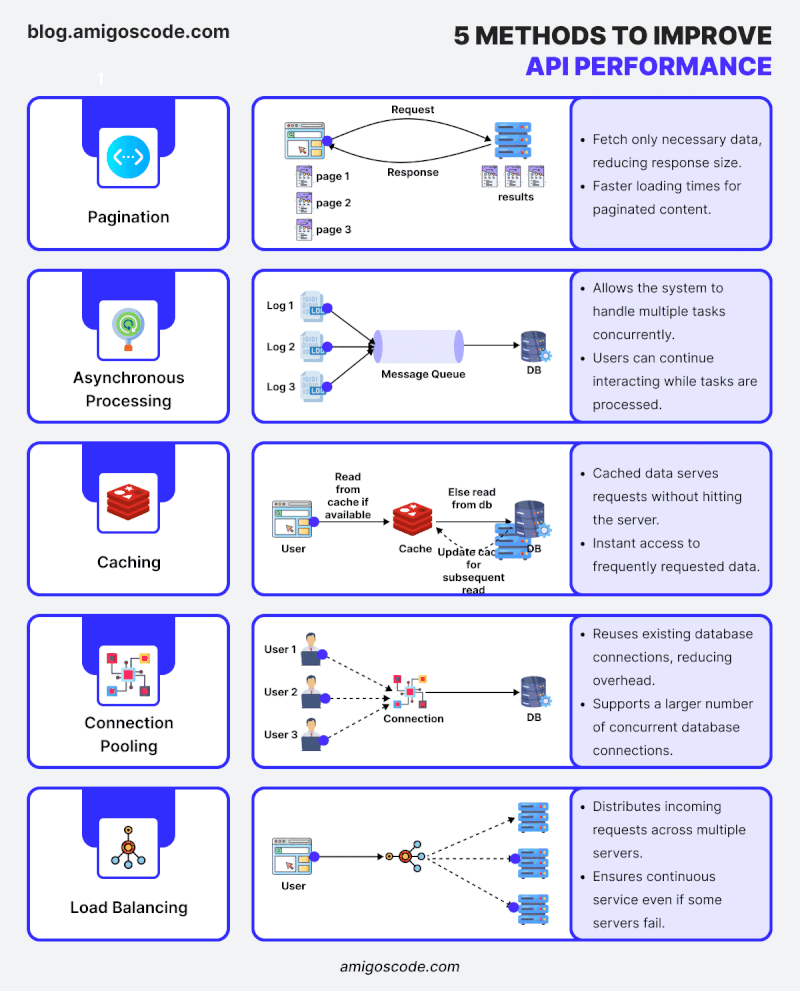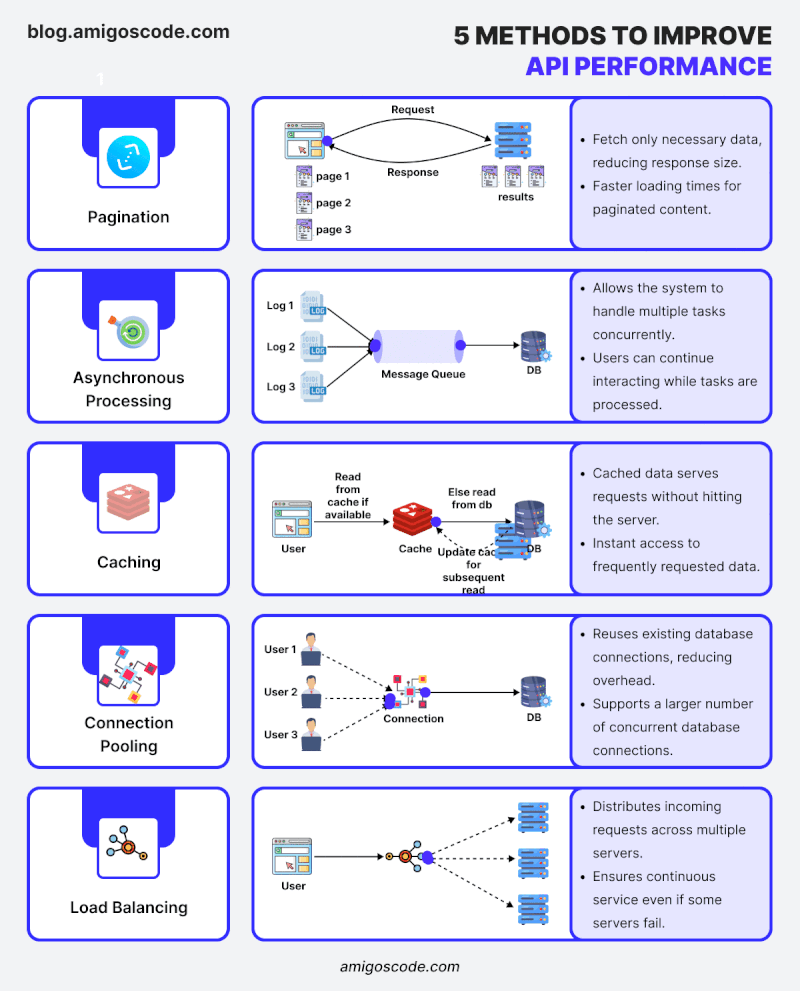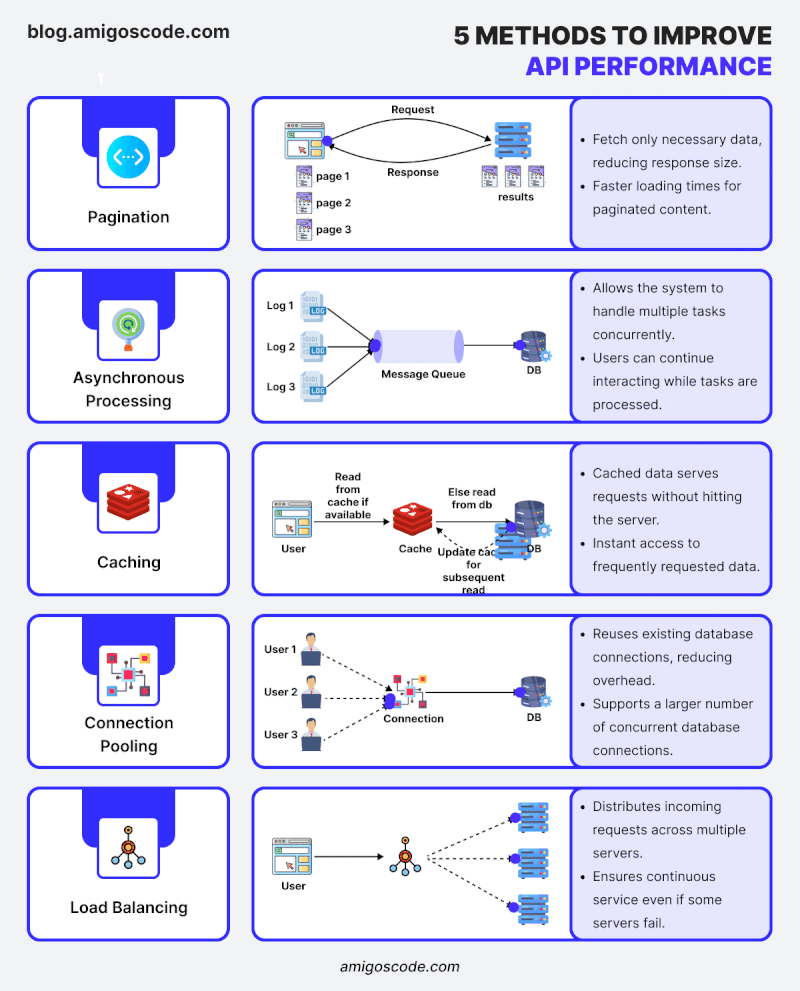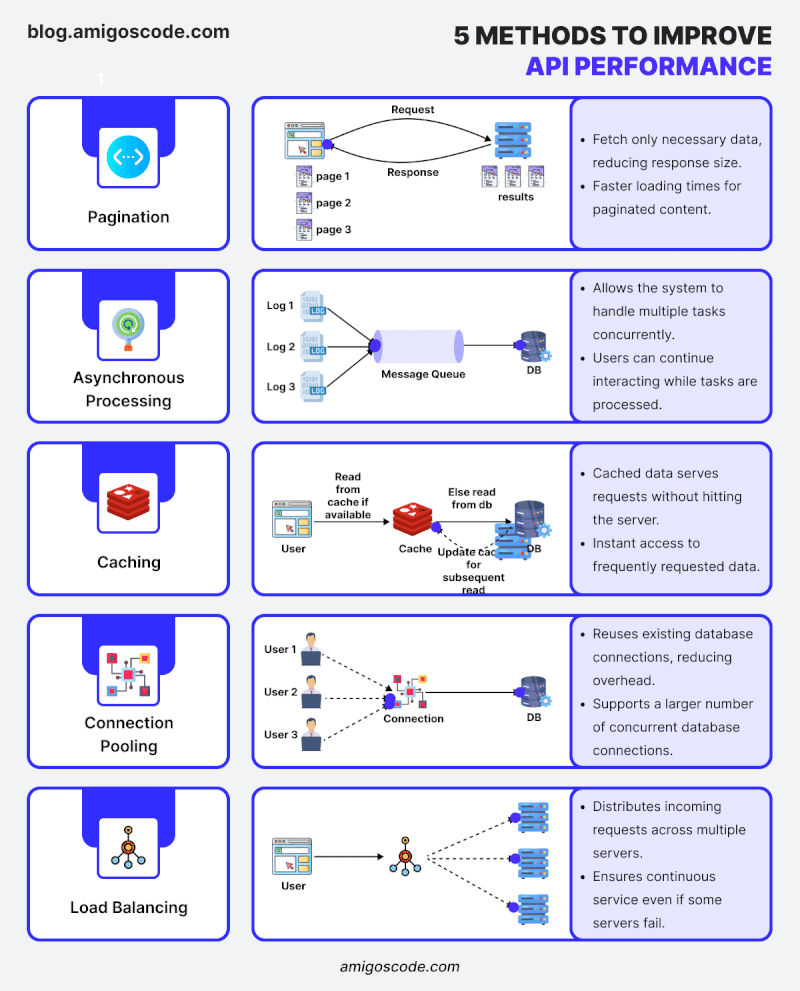
“Bạn có biết rằng 80% thời gian thực thi của một ứng dụng thường tiêu tốn vào việc truy vấn cơ sở dữ liệu không?” Tối ưu hóa cơ sở dữ liệu là một trong những cách hiệu quả nhất để tăng tốc ứng dụng Spring Boot. Bài viết này sẽ hướng dẫn bạn cách thiết kế các truy vấn hiệu quả, sử dụng caching và indexing để cải thiện hiệu năng. Tôi sẽ liệt kê những vấn đề thường gặp trong quá trình lập trình nói chung và lập trình Java Spring Boot nói riêng những critical issue khiến ứng dụng ngày càng nặng nề và chậm chạp
1. Sử dụng vòng for gọi truy vấn SQL
Vấn đề
Khi xử lý dữ liệu từ cơ sở dữ liệu trong ứng dụng Spring Boot, một lỗi thường gặp là sử dụng vòng for để gọi truy vấn SQL nhiều lần. Điều này có thể dẫn đến việc làm quá tải cơ sở dữ liệu và giảm hiệu suất của ứng dụng. Dưới đây là một ví dụ minh họa và cách tối ưu hóa nó.
Giả sử chúng ta có một danh sách các userId và cần lấy thông tin chi tiết của từng người dùng từ cơ sở dữ liệu. Dưới đây là cách không tối ưu khi sử dụng vòng for để gọi truy vấn SQL:
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void fetchUserDetails(List<Integer> userIds) {
for (Integer userId : userIds) {
// Truy vấn SQL được gọi lặp lại trong mỗi lần lặp của vòng for
var user = userRepository.findById(userId)
}
}
}
Vấn đề với ví dụ không tối ưu
- Hiệu suất kém: Mỗi lần lặp lại vòng for, một truy vấn SQL mới được thực hiện, gây tải nặng cho cơ sở dữ liệu và làm chậm ứng dụng.
- Dễ gây lỗi quá tải: Với một danh sách userId lớn, cơ sở dữ liệu có thể bị quá tải và dẫn đến lỗi kết nối hoặc thậm chí crash ứng dụng.
Giải pháp
Thay vì thực hiện truy vấn SQL nhiều lần trong vòng for, ta có thể tối ưu hóa bằng cách sử dụng một truy vấn duy nhất để lấy tất cả dữ liệu cần thiết cùng một lúc.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void fetchUserDetails(List<Integer> userIds) {
// Xây dựng câu truy vấn với danh sách userId
var userLists = userRepository.findAllById(List.of(1,2,4,5,6));
}
}
Lợi ích của cách tiếp cận tối ưu:
- Giảm tải cho cơ sở dữ liệu: Thực hiện một truy vấn duy nhất cho tất cả userId, giảm thiểu số lượng kết nối đến cơ sở dữ liệu và cải thiện hiệu suất.
- Tiết kiệm thời gian: Giảm thời gian thực thi tổng thể của ứng dụng do chỉ có một truy vấn SQL được thực hiện thay vì nhiều truy vấn.
- Bảo trì dễ dàng hơn: Mã nguồn rõ ràng hơn và dễ bảo trì do tránh được các lỗi tiềm ẩn từ việc lặp lại truy vấn nhiều lần.
Kết luận
Hướng dẫn này sẽ giúp bạn tránh những lỗi phổ biến khi sử dụng vòng for để gọi truy vấn SQL trong Spring Boot và cung cấp cách tiếp cận tối ưu hóa cho ứng dụng của bạn.
2. Query loop N+1 khi sử dụng Hibernate LAZY type = EAGER chưa hợp lý
Vấn đề
Khi làm việc với Hibernate trong Spring Boot, một trong những khái niệm quan trọng cần hiểu là cách tải dữ liệu liên quan (fetching) từ cơ sở dữ liệu. Hibernate hỗ trợ hai kiểu tải dữ liệu chính: LAZY và EAGER.
FetchType.LAZY(Tải lười biếng): Dữ liệu liên quan không được tải ngay lập tức khi đối tượng chính được tải. Dữ liệu này chỉ được tải khi cần thiết, giúp tiết kiệm bộ nhớ và tăng hiệu suất khi không cần sử dụng dữ liệu liên quan ngay lập tức.FetchType.EAGER(Tải tức thì): Dữ liệu liên quan được tải ngay lập tức cùng với đối tượng chính, ngay cả khi dữ liệu đó có thể không cần thiết. Điều này có thể dẫn đến vấn đề hiệu suất nếu dữ liệu liên quan lớn hoặc không cần thiết.
Ví dụ: Sử dụng FetchType.LAZY và FetchType.EAGER
Giả sử chúng ta có hai thực thể (entity) trong một ứng dụng quản lý sinh viên và khóa học: Student và Course. Một sinh viên có thể tham gia nhiều khóa học, tạo ra mối quan hệ ManyToMany giữa Student và Course.
//1. Định nghĩa Entity `Student`
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
@Table(name="student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinColumn(
name = "course_id"
)
private Course course;
// Getters and Setters
}```
//fetch = FetchType.LAZY: Khóa học của sinh viên (courses) sẽ chỉ được tải khi truy cập vào thuộc tính courses của đối tượng Student.
// 2. Định nghĩa Entity Course
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
@Table(name="course")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "courses", fetch = FetchType.EAGER)
private Set<Student> students = new HashSet<>();
// Getters and Setters
}
//fetch = FetchType.EAGER: Các sinh viên tham gia khóa học (students) sẽ được tải ngay lập tức khi đối tượng Course được tải.
Sự Khác Biệt giữa FetchType.LAZY và FetchType.EAGER
FetchType.LAZY:
- Lợi ích: Tăng hiệu suất bằng cách không tải dữ liệu khóa học ngay lập tức.
- Hạn chế: Khi cần truy cập dữ liệu khóa học, sẽ có một truy vấn bổ sung đến cơ sở dữ liệu.
FetchType.EAGER:
- Lợi ích: Truy cập dữ liệu liên quan (sinh viên) mà không cần thêm truy vấn.
- Hạn chế: Tải toàn bộ dữ liệu liên quan có thể gây ra hiệu suất kém nếu dữ liệu quá lớn hoặc không cần thiết, gây lên tình trạng query N+1.
Giải pháp
Để hạn chế việc loop query N+1 khi sử dụng lazy type = EAGER thì chúng ta sẽ sử dụng lazy type = LAZY và gom các đối tượng liên quan gọi 1 lần xuống database để lấy toàn bộ dữ liệu thay vì dùng lazy type = EAGER
Ví dụ:
public class ClassServiceImpl{
private CourceRepository courceRepository;
private CoursetMapper coursetMapper;
private StudentRepository studentRepository;
private StudentMapper studentMapper;
public List<Course> fetchListStudent(){
// Lấy danh sách Course từ database.
var courseListEntity = courceRepository.findAll();
// Sử dụng DTO để chuyển đổi dữ liệu từ entity sang dto để trả ra cho end-user. [Tại sao phải dùng DTO](https://viblo.asia/p/entity-domain-model-va-dto-sao-nhieu-qua-vay-YWOZroMPlQ0)
var courseListResponse = coursetMapper.toTarget(courseListEntity);
// Lấy danh sách studentIds để query xuống database lấy dữ liệu student theo course;
var studentIds = courseListResponse.getStudents().stream().map(s->s.getId()).collect(Collector.toSet()));
var studentLists = studentRepository.findAllByIds(studentIds);
var studentResponse = studentMapper.toTarget(studentLists);
var studentGroupByCourse = studentResponse.stream().map(f->studentMapper.toTarget(f)).collect(Collector.groupBy(f->f.getCource().getId())));
courseListResponse.forEach(f->){
if(studentGroupByCourse.containKey(f.getId()){
f.setStudents(studentGroupByCourse.get(f.getId));
}
}
return courseListResponse;
}
}
Việc sử dụng DTO, entity, và collection Map kết hợp với nhau để giúp việc lấy dữ liệu thuận lợi hơn và dễ thao tác trong quá trình coding và làm tăng performance lên rõ dệt so với việc sử dụng lazy type = EAGER
Kết luận
Qua ví dụ trên bạn đã hiểu được cách khắc phục khi xử lý các đối tượng có quan hệ trong hibernate, việc gom nhóm các đối tượng liên quan để gọi xuống database lấy dữ liệu sẽ tối ưu gấp nhiều lần so với việc sử dụng lazy type = EAGER.
Đặc biệt với các ứng dụng có lượng traffic lớn, hàng triệu, trăm triệu request mỗi ngày, việc tối ưu giảm được thêm 1 query sẽ tiết kiệm được hàng triệu query khác vậy nên hãy cẩn trọng với những gì bạn viết!
3. Xử lý Đồng bộ hóa (Synchronization) không hợp lý
Vấn đề
Việc sử dụng đồng bộ hóa (synchronization) trong Java là cần thiết để đảm bảo tính nhất quán dữ liệu khi nhiều luồng cùng truy cập và thay đổi cùng một tài nguyên. Tuy nhiên, nếu không được sử dụng hợp lý, đồng bộ hóa có thể gây ra nhiều vấn đề về hiệu suất, bao gồm “thread contention” (xung đột luồng) và “deadlock” (bế tắc).
Giả sử chúng ta có một ứng dụng xử lý giao dịch tài khoản ngân hàng, với phương thức withdraw (rút tiền) và deposit (nạp tiền) trong lớp BankAccount. Để đảm bảo tính nhất quán của dữ liệu, chúng ta sử dụng từ khóa synchronized để đồng bộ hóa tất cả các phương thức.
public class BankAccount {
private double balance;
public BankAccount(double initialBalance) {
this.balance = initialBalance;
}
// Phương thức synchronized để đồng bộ hóa truy cập rút tiền
public synchronized void withdraw(double amount) {
if (balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount + ", New Balance: " + balance);
} else {
System.out.println("Insufficient balance");
}
}
// Phương thức synchronized để đồng bộ hóa truy cập nạp tiền
public synchronized void deposit(double amount) {
balance += amount;
System.out.println("Deposited: " + amount + ", New Balance: " + balance);
}
// Phương thức synchronized để kiểm tra số dư
public synchronized double getBalance() {
return balance;
}
}
Vấn đề với Ví dụ không hợp lý
- Quá nhiều khóa đồng bộ hóa: Tất cả các phương thức của BankAccount đều được đồng bộ hóa bằng từ khóa synchronized. Điều này khiến cho mỗi khi một luồng truy cập vào một trong các phương thức này, toàn bộ đối tượng BankAccount bị khóa.
- Gây ra “thread contention”: Do tất cả các phương thức bị khóa, chỉ một luồng có thể truy cập bất kỳ phương thức nào tại một thời điểm. Điều này gây ra tình trạng chờ đợi lâu (thời gian chờ tăng) khi nhiều luồng cần truy cập đồng thời.
- Hiệu suất kém: Đồng bộ hóa không hợp lý làm chậm hiệu suất của ứng dụng, đặc biệt là khi các thao tác không thực sự cần thiết phải được đồng bộ hóa.
Giải pháp
Để tối ưu hóa, chúng ta chỉ nên đồng bộ hóa các đoạn mã thực sự cần thiết thay vì toàn bộ phương thức. Trong trường hợp này, chúng ta chỉ cần đồng bộ hóa truy cập đến phần thay đổi biến balance. Hay nói chung chúng ta sẽ chỉ sử dụng đồng bộ hóa trong việc thêm mới/update dữ liệu nơi mà yêu cầu việc đồng bộ hóa giữa các luồng(thread) điều này đảm bảo các giao dịch đảm bảo tính consistency, tránh việc xung đột trong việc update/thêm mới dữ liệu giữa nhiều luồng trong môi trường multiple threads.
public class BankAccount {
private double balance;
public BankAccount(double initialBalance) {
this.balance = initialBalance;
}
// Phương thức nạp tiền với đồng bộ hóa chỉ phần cần thiết
public void withdraw(double amount) {
synchronized (this) {
if (balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount + ", New Balance: " + balance);
} else {
System.out.println("Insufficient balance");
}
}
}
// Phương thức nạp tiền với đồng bộ hóa chỉ phần cần thiết
public void deposit(double amount) {
synchronized (this) {
balance += amount;
System.out.println("Deposited: " + amount + ", New Balance: " + balance);
}
}
// Phương thức kiểm tra số dư không cần đồng bộ hóa vì chỉ đọc dữ liệu
public double getBalance() {
return balance;
}
}
Lợi ích của Cách Tiếp cận Tối ưu hóa
- Giảm thời gian chờ đợi: Bằng cách chỉ đồng bộ hóa phần mã cần thiết, chúng ta giảm thiểu việc khóa toàn bộ đối tượng BankAccount. Điều này giúp các luồng khác có thể truy cập vào các phương thức không bị đồng bộ hóa (như getBalance) mà không cần chờ đợi.
- Cải thiện hiệu suất: Việc đồng bộ hóa ít hơn giúp cải thiện hiệu suất tổng thể của ứng dụng vì ít luồng bị chặn hơn.
- Tránh xung đột luồng (Thread Contention): Bằng cách giảm số lượng khóa, chúng ta giảm thiểu khả năng xảy ra xung đột giữa các luồng khi truy cập tài nguyên được chia sẻ.
Kết luận
Việc sử dụng đồng bộ hóa một cách hợp lý là rất quan trọng trong lập trình đa luồng. Bằng cách đồng bộ hóa chỉ phần mã thực sự cần thiết, bạn có thể tránh các vấn đề về hiệu suất và xung đột luồng, đảm bảo ứng dụng hoạt động trơn tru và hiệu quả hơn.
4. Xử lý Dữ liệu Không Hiệu quả
Vấn đề
Trong ứng dụng Spring Boot, xử lý dữ liệu không hiệu quả có thể dẫn đến các vấn đề nghiêm trọng như giảm hiệu suất, tiêu tốn tài nguyên hệ thống, và thời gian phản hồi lâu. Dưới đây là một ví dụ minh họa về cách xử lý dữ liệu không hiệu quả và cách tối ưu hóa.
Giả sử chúng ta có một ứng dụng Spring Boot cần lấy tất cả bản ghi từ một bảng lớn trong cơ sở dữ liệu, sau đó áp dụng một số bộ lọc và chuyển đổi dữ liệu trong mã Java.
Giả sử chúng ta có một bảng Employee với hàng triệu bản ghi. Dưới đây là cách không hiệu quả để lấy và xử lý tất cả dữ liệu:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
@Service
public class EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
public List<EmployeeDTO> getFilteredEmployees() {
// Lấy tất cả dữ liệu từ cơ sở dữ liệu
List<Employee> employees = employeeRepository.findAll();
// Áp dụng bộ lọc và chuyển đổi dữ liệu trong mã Java
return employees.stream()
.filter(emp -> emp.getAge() > 30) // Lọc các nhân viên trên 30 tuổi
.map(emp -> new EmployeeDTO(emp.getId(), emp.getName())) // Chuyển đổi sang DTO
.collect(Collectors.toList());
}
}
Vấn đề xảy ra ở đây:
- Lấy tất cả dữ liệu từ cơ sở dữ liệu: Phương thức findAll() tải toàn bộ dữ liệu từ bảng Employee, điều này không hiệu quả khi bảng chứa hàng triệu bản ghi.
- Xử lý dữ liệu trong mã Java: Áp dụng bộ lọc và chuyển đổi dữ liệu trong mã Java thay vì sử dụng truy vấn SQL tối ưu hóa, dẫn đến tiêu tốn tài nguyên bộ nhớ và thời gian xử lý lâu.
- Gây ra lỗi “OutOfMemoryError”: Với lượng dữ liệu lớn, việc tải toàn bộ vào bộ nhớ có thể dẫn đến lỗi “OutOfMemoryError”.
Giải pháp
Thay vì tải toàn bộ dữ liệu và xử lý trong mã Java, chúng ta nên sử dụng các truy vấn tùy chỉnh với SQL hoặc JPQL để chỉ lấy dữ liệu cần thiết từ cơ sở dữ liệu.
//Repository
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface EmployeeRepository extends JpaRepository<Employee, Long> {
// Sử dụng JPQL để chỉ lấy dữ liệu cần thiết
@Query("SELECT new com.example.EmployeeDTO(e.id, e.name) FROM Employee e WHERE e.age > 30")
List<EmployeeDTO> findEmployeesAboveAge30();
}
//Service
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
public List<EmployeeDTO> getFilteredEmployees() {
// Lấy dữ liệu cần thiết từ cơ sở dữ liệu bằng truy vấn tối ưu
return employeeRepository.findEmployeesAboveAge30();
}
}
Lợi ích của Cách Tiếp cận này:
- Giảm tải trên cơ sở dữ liệu: Chỉ lấy dữ liệu cần thiết từ cơ sở dữ liệu, giảm thiểu lượng dữ liệu được tải vào bộ nhớ.
- Hiệu suất cao hơn: Áp dụng bộ lọc và chuyển đổi dữ liệu tại cơ sở dữ liệu thay vì trong mã Java, giúp cải thiện thời gian phản hồi và sử dụng tài nguyên hiệu quả.
- Tránh lỗi “OutOfMemoryError”: Bằng cách giới hạn lượng dữ liệu tải vào bộ nhớ, giảm nguy cơ gặp phải lỗi “OutOfMemoryError”.
Kết luận
Xử lý dữ liệu một cách tối ưu trong ứng dụng Spring Boot là rất quan trọng để đảm bảo hiệu suất và tính ổn định của ứng dụng. Sử dụng truy vấn tùy chỉnh để chỉ lấy dữ liệu cần thiết từ cơ sở dữ liệu là một trong những phương pháp tốt nhất để đạt được điều này.
5. Quản lý Bộ Nhớ Không Hiệu Quả
Vấn đề
Quản lý bộ nhớ không hiệu quả trong ứng dụng Spring Boot có thể dẫn đến các vấn đề như tiêu tốn bộ nhớ, giảm hiệu suất, hoặc thậm chí gây ra lỗi “OutOfMemoryError”. Dưới đây là một ví dụ minh họa về cách quản lý bộ nhớ không hiệu quả và cách tối ưu hóa để cải thiện hiệu suất.
Giả sử chúng ta có một ứng dụng Spring Boot cần xử lý danh sách người dùng và lưu trữ kết quả trong bộ nhớ để sử dụng cho các xử lý khác. Tuy nhiên, thay vì sử dụng cấu trúc dữ liệu hiệu quả hoặc kỹ thuật quản lý bộ nhớ hợp lý, ứng dụng lại sử dụng cách tiếp cận không tối ưu.
Giả sử chúng ta có một phương thức processUsers() trong một lớp UserService xử lý danh sách người dùng và lưu trữ kết quả trong một List toàn cục (global).
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
// Danh sách toàn cục để lưu trữ người dùng đã xử lý
private List<User> processedUsers = new ArrayList<>();
public void processUsers() {
// Lấy tất cả người dùng từ cơ sở dữ liệu
List<User> users = userRepository.findAll();
// Xử lý từng người dùng và thêm vào danh sách toàn cục
for (User user : users) {
// Giả định một số xử lý nặng về bộ nhớ
processUser(user);
processedUsers.add(user);
}
}
private void processUser(User user) {
// Xử lý phức tạp tốn nhiều bộ nhớ
user.setName(user.getName().toUpperCase());
}
}
Vấn đề không tối ưu:
- Lưu trữ Dữ liệu Lâu Dài trong Bộ Nhớ: Sử dụng List toàn cục (processedUsers) để lưu trữ dữ liệu sau khi xử lý mà không có chiến lược xóa bỏ hoặc làm sạch bộ nhớ.
- Tiêu tốn Bộ Nhớ Không Cần Thiết: Mọi đối tượng User sau khi xử lý được giữ trong bộ nhớ, dẫn đến việc tiêu tốn bộ nhớ không cần thiết khi số lượng người dùng lớn.
- Nguy cơ Lỗi “OutOfMemoryError”: Khi danh sách processedUsers quá lớn, ứng dụng có thể gặp lỗi “OutOfMemoryError”.
Giải pháp
Thay vì lưu trữ tất cả dữ liệu đã xử lý trong bộ nhớ, chúng ta có thể sử dụng một cách tiếp cận hiệu quả hơn, chẳng hạn như chỉ lưu trữ những dữ liệu cần thiết, sử dụng bộ nhớ tạm thời, hoặc xử lý dữ liệu theo từng lô (batch processing).
- Giải pháp sử dụng Batch Processing và Lưu trữ Tạm Thời
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void processUsers() {
// Lấy tất cả người dùng từ cơ sở dữ liệu theo từng lô nhỏ
int batchSize = 100;
int start = 0;
while (true) {
// Lấy một batch người dùng
List<User> users = userRepository.findUsersWithPagination(start, batchSize);
if (users.isEmpty()) {
break;
}
// Xử lý từng người dùng trong batch
for (User user : users) {
processUser(user);
// Không lưu trữ người dùng trong bộ nhớ dài hạn
}
start += batchSize;
}
}
private void processUser(User user) {
// Xử lý phức tạp tốn nhiều bộ nhớ
user.setName(user.getName().toUpperCase());
}
}
- Repository với Truy vấn Phân Trang
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT u FROM User u ORDER BY u.id ASC")
List<User> findUsersWithPagination(@Param("start") int start, @Param("batchSize") int batchSize);
}
Lợi ích của Cách Tiếp cận Tối ưu hóa
- Giảm Tiêu tốn Bộ Nhớ: Xử lý dữ liệu theo từng lô nhỏ giúp giảm thiểu bộ nhớ cần thiết cho mỗi lần xử lý.
- Cải thiện Hiệu suất: Bằng cách giảm tải dữ liệu lưu trữ lâu dài trong bộ nhớ, ứng dụng có thể xử lý nhanh hơn và tiêu tốn ít tài nguyên hơn.
- Tránh Lỗi “OutOfMemoryError”: Quản lý bộ nhớ hợp lý tránh được lỗi “OutOfMemoryError” khi xử lý dữ liệu lớn.
Kết luận
Quản lý bộ nhớ hiệu quả là một phần quan trọng trong phát triển ứng dụng Spring Boot. Sử dụng các kỹ thuật như batch processing, chỉ lưu trữ dữ liệu cần thiết và làm sạch bộ nhớ kịp thời có thể giúp cải thiện hiệu suất và tính ổn định của ứng dụng.
6. Sử dụng Connection Pool Size
Vấn đề
Trong các ứng dụng Spring Boot, việc sử dụng Connection Pool (bể kết nối) là rất quan trọng để quản lý hiệu quả các kết nối tới cơ sở dữ liệu. Một Connection Pool được cấu hình với một kích thước cụ thể (pool size) để xác định số lượng kết nối đồng thời có thể mở đến cơ sở dữ liệu. Cấu hình kích thước Connection Pool không hợp lý có thể dẫn đến các vấn đề như nghẽn kết nối, giảm hiệu suất, hoặc sử dụng tài nguyên không hiệu quả.
Giải pháp
Tại sao Connection Pool Size quan trọng?
- Tối ưu hóa Tài Nguyên: Giúp tối ưu hóa tài nguyên hệ thống bằng cách tái sử dụng các kết nối cơ sở dữ liệu.
- Giảm Chi Phí Tạo Kết Nối: Mở kết nối tới cơ sở dữ liệu tốn kém về thời gian và tài nguyên; sử dụng Connection Pool giúp giảm thiểu chi phí này.
- Cải thiện Hiệu Suất: Giúp cải thiện hiệu suất ứng dụng khi xử lý nhiều yêu cầu đồng thời bằng cách duy trì số lượng kết nối ổn định.
Dưới đây là ví dụ về cách cấu hình Connection Pool Size cho một ứng dụng Spring Boot sử dụng HikariCP — Connection Pool mặc định của Spring Boot.
- Cấu hình trong
application.propertiesBạn có thể cấu hình kích thước Connection Pool bằng cách thêm các thuộc tính sau vào tệpapplication.properties:
# Cấu hình kết nối cơ sở dữ liệu
spring.datasource.url=jdbc:mysql://localhost:3306/mydatabase
spring.datasource.username=myuser
spring.datasource.password=mypassword
# Cấu hình HikariCP Connection Pool
spring.datasource.hikari.maximum-pool-size=10
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.max-lifetime=1800000
spring.datasource.hikari.connection-timeout=20000
- Cấu hình trong
application.yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydatabase
username: myuser
password: mypassword
hikari:
maximum-pool-size: 10
minimum-idle: 5
idle-timeout: 30000
max-lifetime: 1800000
connection-timeout: 20000
Kết luận
Việc cấu hình đúng Connection Pool Size trong Spring Boot là rất quan trọng để đảm bảo hiệu suất cao và sử dụng tài nguyên hệ thống hiệu quả. HikariCP, Connection Pool mặc định của Spring Boot, cung cấp các tùy chọn cấu hình linh hoạt giúp quản lý kết nối tới cơ sở dữ liệu một cách tối ưu.
Lợi ích của Cấu hình Connection Pool Hợp Lý
- Cải thiện Tốc độ Ứng Dụng: Giảm thời gian kết nối và tái sử dụng kết nối hiệu quả.
- Tối ưu Hóa Tài Nguyên: Giúp tiết kiệm tài nguyên hệ thống và tránh lỗi do quá tải kết nối.
- Đảm bảo Tính Ổn Định: Giảm thiểu nguy cơ kết nối hết hạn hoặc bị từ chối do quá tải.
Hãy đảm bảo rằng bạn chọn kích thước Connection Pool phù hợp với nhu cầu và kiến trúc hệ thống của mình để tối ưu hóa hiệu suất và độ ổn định của ứng dụng.
7.Sử dụng Distributed Database
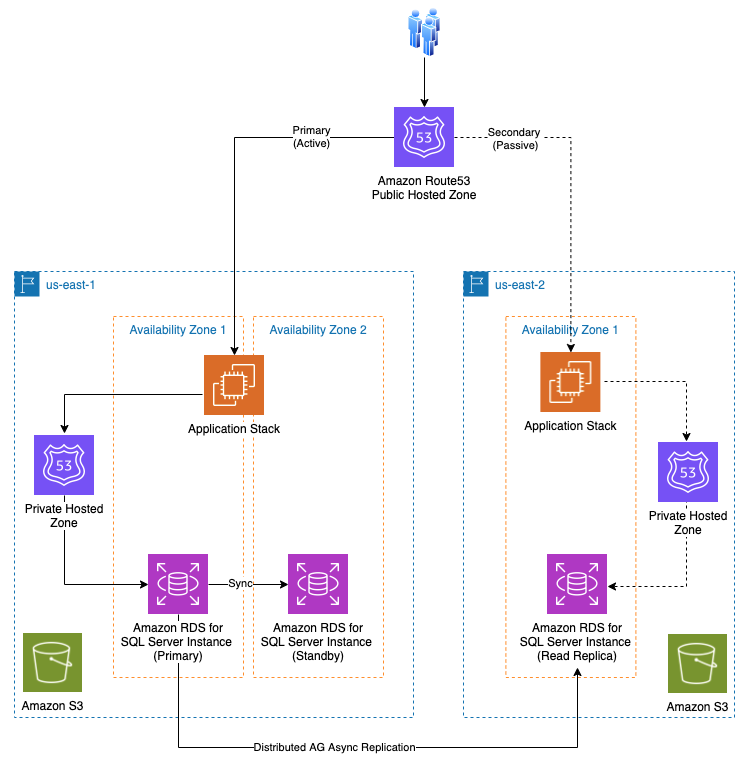
Vấn đề
Trong các ứng dụng quy mô lớn, sử dụng cơ sở dữ liệu phân tán với các endpoint chuyên dụng cho đọc và ghi dữ liệu giúp cải thiện hiệu suất, độ tin cậy và khả năng mở rộng. Mô hình này thường bao gồm một cơ sở dữ liệu chính (master) cho ghi dữ liệu và nhiều cơ sở dữ liệu phụ (replica) để đọc dữ liệu.
Giải pháp
Tại sao sử dụng Read/Write Endpoint trong Cơ sở Dữ liệu Phân Tán?
- Cải thiện Hiệu Suất: Phân chia lưu lượng đọc và ghi giúp giảm tải cho cơ sở dữ liệu chính, cải thiện hiệu suất tổng thể.
- Tăng Độ Tin Cậy: Sử dụng các bản sao để đọc dữ liệu giúp giảm nguy cơ mất mát dữ liệu và tăng khả năng phục hồi.
- Khả Năng Mở Rộng: Dễ dàng mở rộng hệ thống bằng cách thêm nhiều replica phục vụ các yêu cầu đọc.
Kết luận
Việc sử dụng read/write endpoint trong cơ sở dữ liệu phân tán giúp cải thiện hiệu suất và tối ưu hóa tài nguyên của ứng dụng Spring Boot. Bằng cách sử dụng các kỹ thuật như phân loại DataSource, AOP, và quản lý context của DataSource, chúng ta có thể dễ dàng quản lý các kết nối đọc/ghi một cách hiệu quả.
Tổng kết
Trong bài hướng dẫn này mình đã hướng dẫn các bạn tối ưu spring boot application bằng 6 cách kinh điển. Đây là tất cả những gì mình đã áp dụng tại dự án trong quá trình tối ưu hiệu năng cho ứng dụng Core Java Spring Boot Application. Trong bối cảnh ứng dụng web ngày càng phức tạp, việc tối ưu hóa hiệu năng ứng dụng là một yêu cầu không thể thiếu. Bài viết đã tập trung vào các bottleneck thường gặp trong ứng dụng Spring Boot và đưa ra các giải pháp cụ thể. Tuy nhiên, việc tối ưu hóa còn liên quan đến nhiều yếu tố khác như cơ sở dữ liệu, mạng, và phần cứng. Trong tương lai, với sự phát triển của các công nghệ mới, chúng ta có thể kỳ vọng sẽ có thêm nhiều công cụ và phương pháp tối ưu hóa hiệu quả hơn nữa.