3. Các cách tối ưu hóa ứng dụng Xử Lý Hàng Triệu Request
Tổng quan kiến trúc
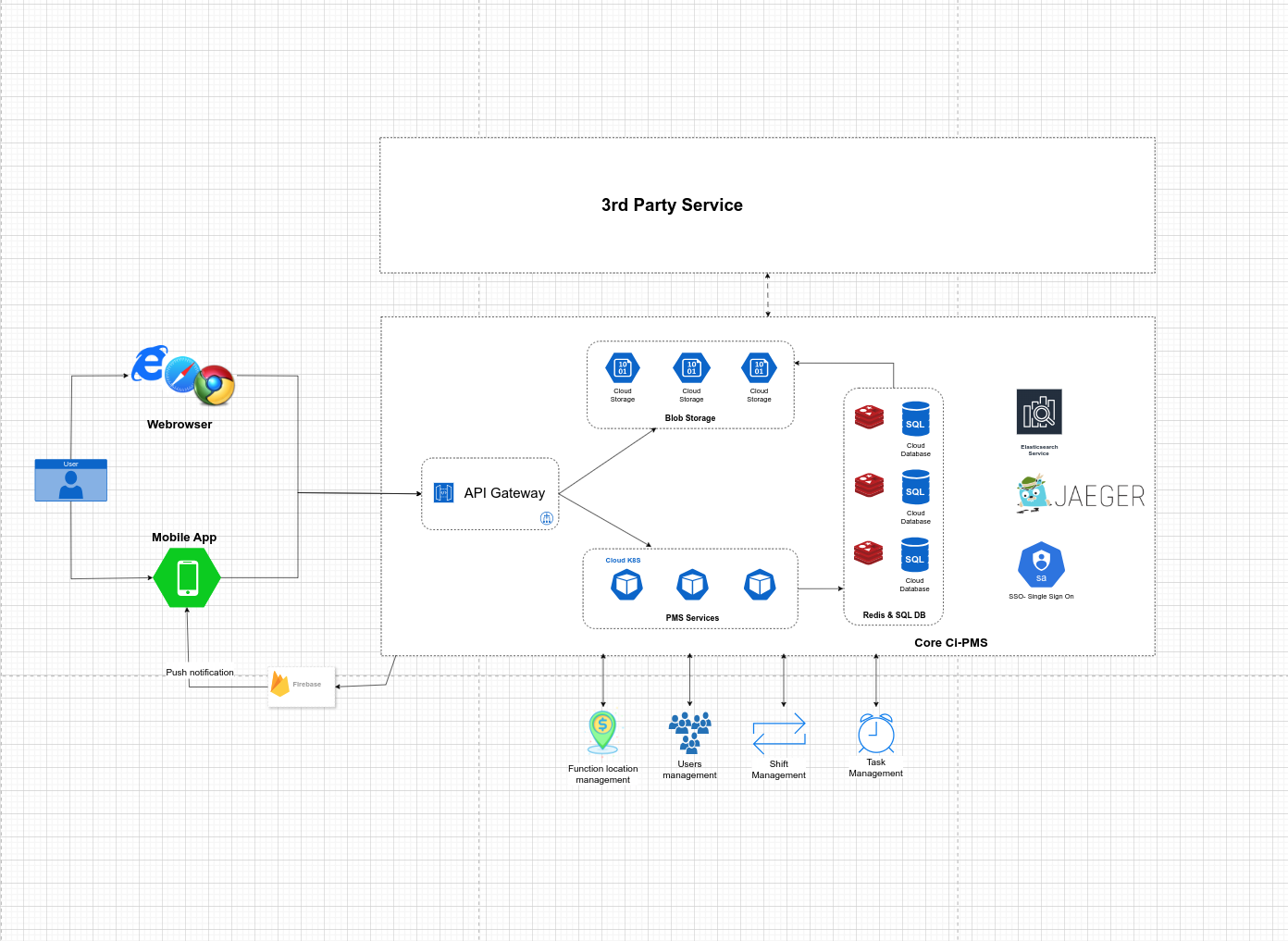
Hệ thống được phát triển dựa trên kiến trúc microservice , mỗi service sẽ thực hiện các nhiệm vụ, chịu trách nhiệm dựa trên domain business logic mà nó được định nghĩa. Hệ thống được xây dựng trên core Java Application sử dụng Spring Boot Framework, Spring Data JPA, Spring Cache, Hibernate… và các thư viện kinh điển như Apache Kafka, Elastic Search …
Việc phân chia ứng dụng ra các service khác nhau giúp việc quản lý dễ dàng hơn trong việc maintain, xử lý dữ liệu , giúp tăng hiệu quả trong quá trình scale up ứng dụng không bị giới hạn như kiến trúc mothonic kiểu cũ. Ứng dụng hiện đang chạy trên PRODUCTION, vì là ứng dụng cho toàn bộ nhân viên công ty X nên hằng ngày sẽ có 8.000 - 10.000 user hoạt động mỗi ngày, với lượng request cần xử lý lên tới hàng triệu traffic mỗi ngày.
Hiện trạng
Trong 1 thời dài gian chạy, ứng dụng phát triển lên hàng chục nghìn user, phát sinh hàng triệu request mỗi này, nên việc đọc/ghi dữ liệu liên tục khiến lượng data lớn được lưu trữ trong database, CPU Database thường xuyên đạt ngưỡng 100%, các APIs có thời gian phản hồi chậm, người dùng thường xuyên phàn nàn ứng dụng đơ, lác, thời gian chờ đợi lâu, ghi nhận các apis có thời gian phản hồi trên 10s lớn.
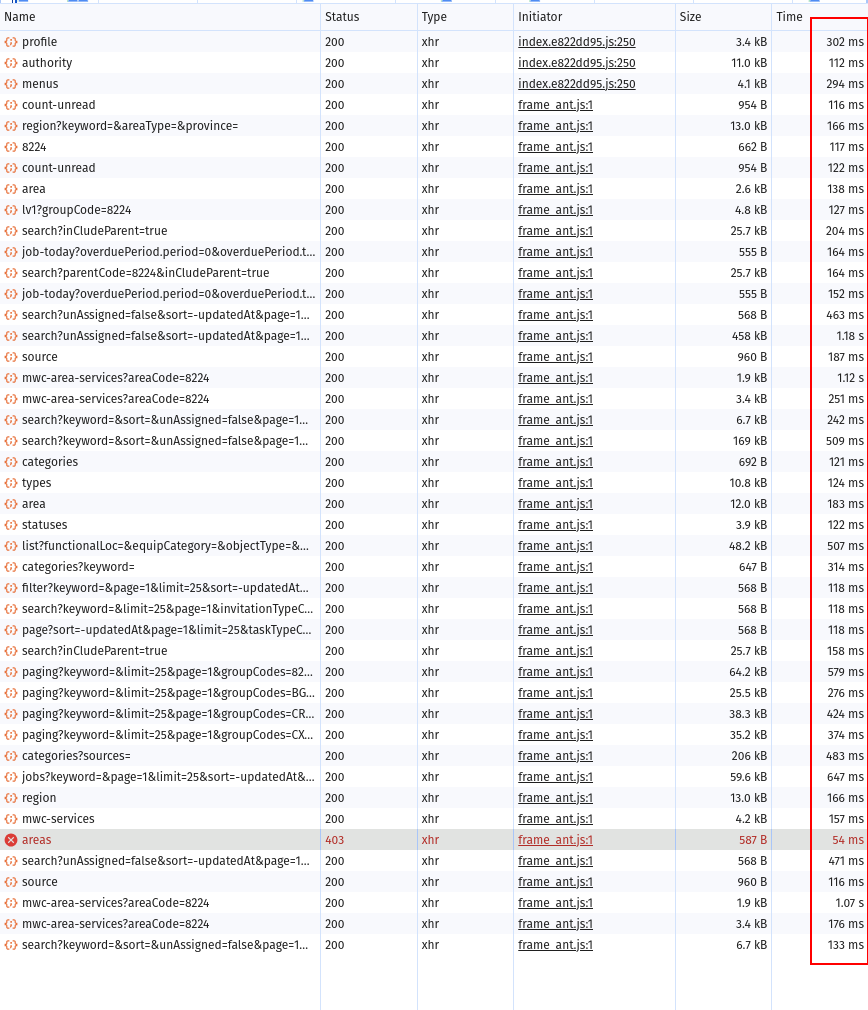
 Danh sách các api,service có thời gian phản hồi lớn > 5s, 10s.
Danh sách các api,service có thời gian phản hồi lớn > 5s, 10s.
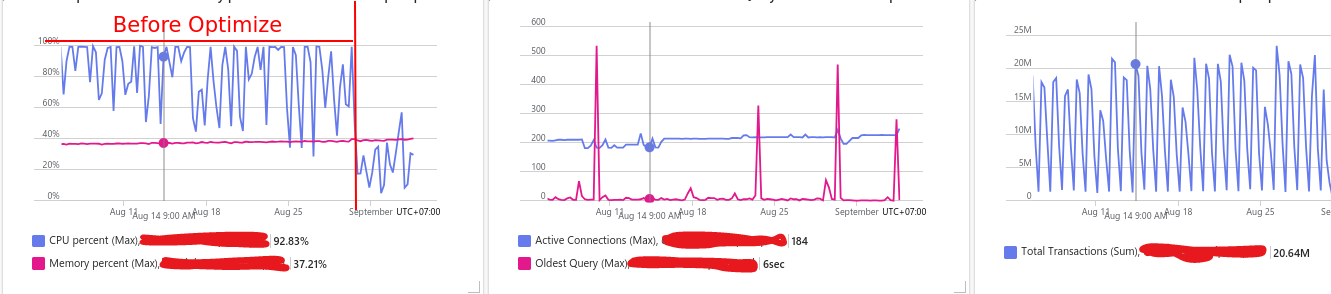
CPU database thường xuyên đạt ngưỡng 100%.
Nguyên nhân của việc quá tải
1. Lưu lượng truy cập tăng
 Việc ứng dụng phát triển đem lại lợi ích nhưng cũng đồng thời là thách thức cho việc đảm bảo ứng dụng hoạt động tốt, trơn tru, việc có hàng 100- 10000 người dùng mỗi ngày sẽ làm số lượng request tăng đột
biến, liên quan đến việc mở rộng ứng dụng kịp thời đáp ứng lưu lượng truy cập cao
Việc ứng dụng phát triển đem lại lợi ích nhưng cũng đồng thời là thách thức cho việc đảm bảo ứng dụng hoạt động tốt, trơn tru, việc có hàng 100- 10000 người dùng mỗi ngày sẽ làm số lượng request tăng đột
biến, liên quan đến việc mở rộng ứng dụng kịp thời đáp ứng lưu lượng truy cập cao
2. Code chưa tối ưu
Nguyên nhân 1 phần lớn do việc phát triển nóng, các tính năng được phản triển liên tục theo mô hình agile chưa có nhiều thời gian để tối ưu, việc kiểm soát code vẫn chưa chặt khiến những dòng code chưa thực sự tốt, chưa thực sự tối ưu đã được đưa lên production khiến ứng dụng đã chậm nay còn chậm thêm, APIs liên tục bị 503-Service Unavailable, 504-Gateway Time-out do lượng truy cập tăng đột biến, ứng dụng k kịp scale nên sẽ xảy ra tình trạng quá tải.
3. SQL Query chưa tối ưu.
Nguyên nhân phần lớn của việc quá tải này là do SQL Query có query cost lớn, chiếm lượng lớn CPU trong quá trình thực hiện, dưới đây có thể là 1 số nguyên nhân:
- Các câu query được sử dụng nhiều , query cost lớn chưa tối ưu.
- Sử dụng quá nhiều subquery khiến query chậm chạp.
- Select toàn bộ bảng, thiếu việc chọn lọc các trường cần thiết.
- Query full scan table, chưa thiết kế indexed hợp lý, khiến các câu query ít được sử dụng lại đánh query, còn các query return lượng dữ liệu lớn lại không dùng hoặc không áp dụng index.
- Không chia partition với các bảng dữ liệu lớn, không limit kết quả theo truy vấn where ….
- Lạm dụng việc sử dụng group by, having.
- Không hiểu, không biết cách phân tích chiến lược thực thi của các câu lệnh SQL, từ đó dẫn đến query không tối ưu, tốn nhiều chi phí thực hiện.
4. Áp dụng cache chưa hợp lý
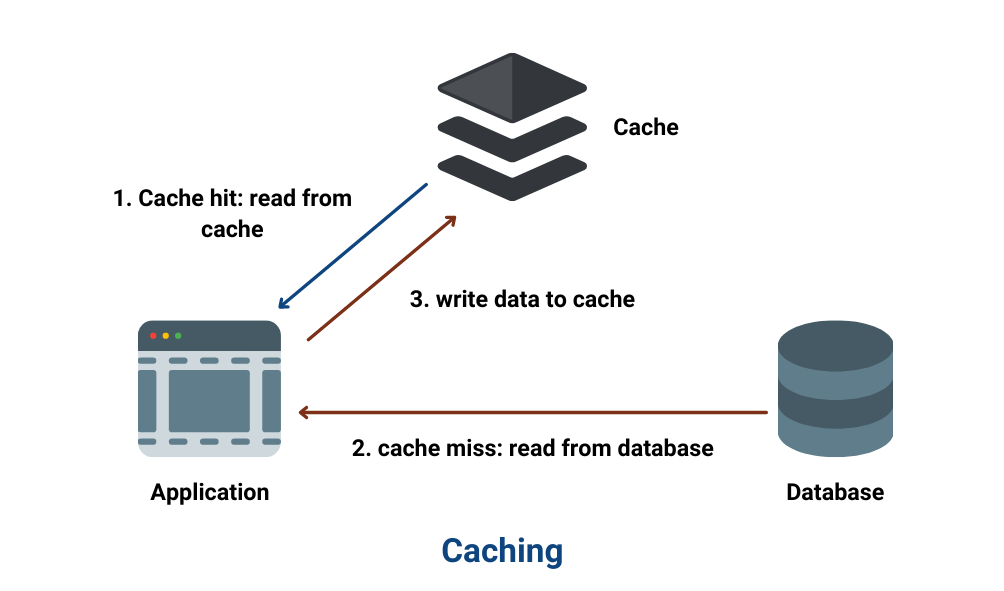 Việc sử dụng cache rất quan trọng trong việc tối ưu, đối với các data ít thay đổi, có thể tái sử dụng chúng ta nên sử dụng cache để tối ưu hóa hiệu năng, thay vì mỗi lần lấy dữ liệu chúng ta cần mở kết nối tới database
và lấy dữ liệu thì chúng ta sẽ sử dụng cache, application sẽ đọc dữ liệu từ cache và trả ra cho end-user nên độ trễ của APIs sẽ giảm xuống miliseconds giúp tăng hiệu năng của APIs đáp ứng hàng trăm nghìn, đến hàng triệu request mỗi giây.
Tuy nhiên việc sử dụng cache cũng đòi hỏi chiến lược invalid cache, update cache chặt chẽ vì nếu không chặt chẽ sẽ xảy ra tình trạng việc data bị sai, thiếu, thừa so với dữ liệu trong database.
Việc sử dụng cache rất quan trọng trong việc tối ưu, đối với các data ít thay đổi, có thể tái sử dụng chúng ta nên sử dụng cache để tối ưu hóa hiệu năng, thay vì mỗi lần lấy dữ liệu chúng ta cần mở kết nối tới database
và lấy dữ liệu thì chúng ta sẽ sử dụng cache, application sẽ đọc dữ liệu từ cache và trả ra cho end-user nên độ trễ của APIs sẽ giảm xuống miliseconds giúp tăng hiệu năng của APIs đáp ứng hàng trăm nghìn, đến hàng triệu request mỗi giây.
Tuy nhiên việc sử dụng cache cũng đòi hỏi chiến lược invalid cache, update cache chặt chẽ vì nếu không chặt chẽ sẽ xảy ra tình trạng việc data bị sai, thiếu, thừa so với dữ liệu trong database.
Giải pháp cho vấn đề
Sau khi đã tìm được nguyên nhân chúng ta sẽ tiếp tục giải pháp cho vấn đề, để giải quyết được vấn đề chúng ta cần biết gốc rễ tại sao code chưa tối ưu? tại sao query chưa tối ưu từ đó sẽ tìm được cách khắc phục.
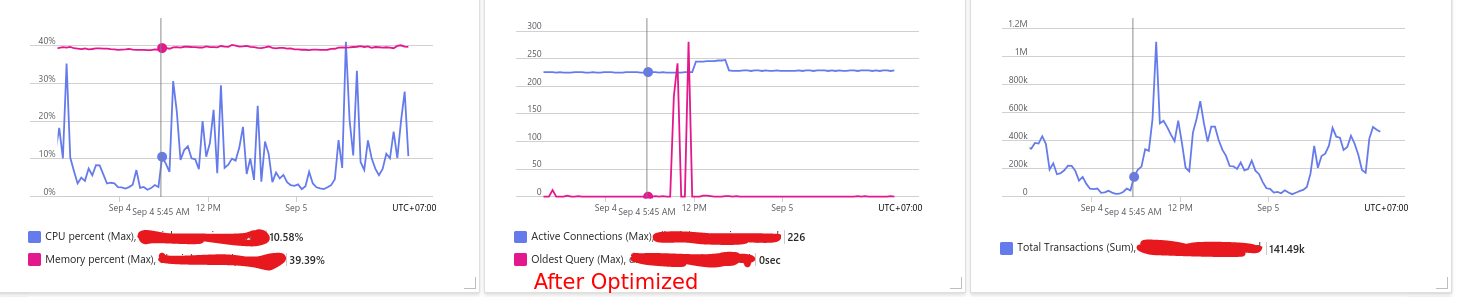
Và đây là kết quả sau khi đã optimized, hiệu năng tăng lên đáng kể thời gian xử lý trung bình của api giao động 100-300ms, không ghi nhận CPU database > 50%, như các bạn có thể thấy trong 1 ngày các service có thể xử lý hàng triệu request mà không gặp vấn đề nào về hiệu năng,
đó là tiền đề để ứng dụng có thể mở rộng và tăng trưởng hơn nữa.

 Cùng tìm hiểu cùng mình những sai lầm phổ biến khi lập trình và cách xử lý cho từng vấn đề qua loạt bài tối ưu code cho Java Application và SQL(Postgresql).
Cùng tìm hiểu cùng mình những sai lầm phổ biến khi lập trình và cách xử lý cho từng vấn đề qua loạt bài tối ưu code cho Java Application và SQL(Postgresql).