1. Top Tips Optimize Spring-boot Performance
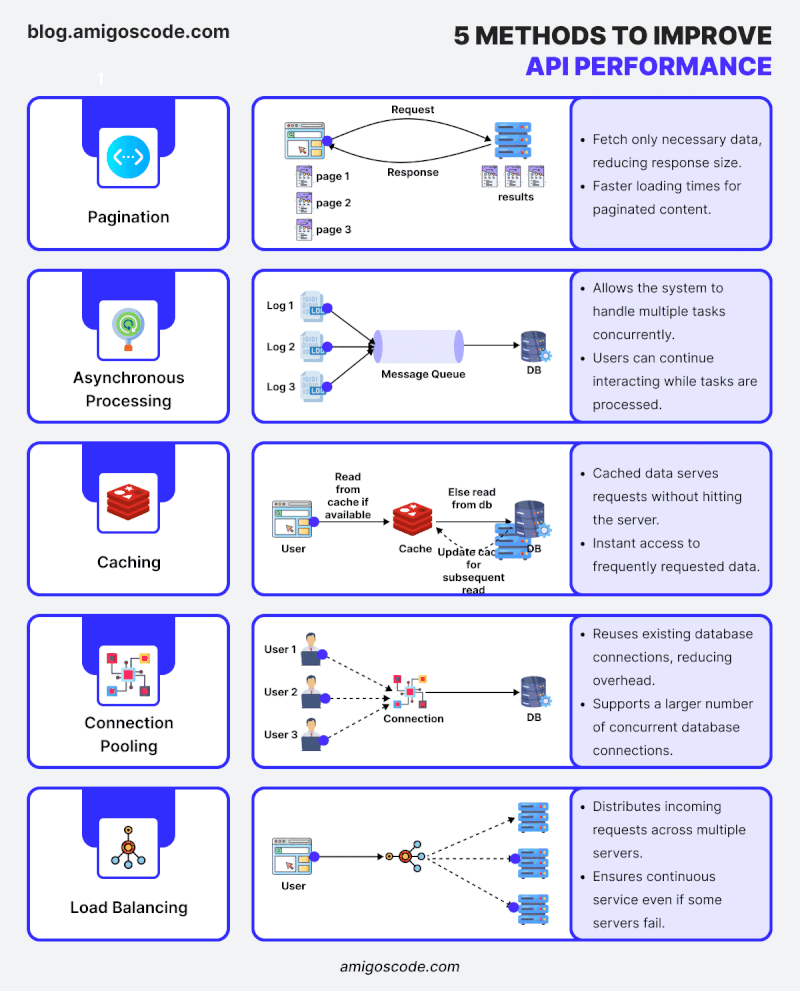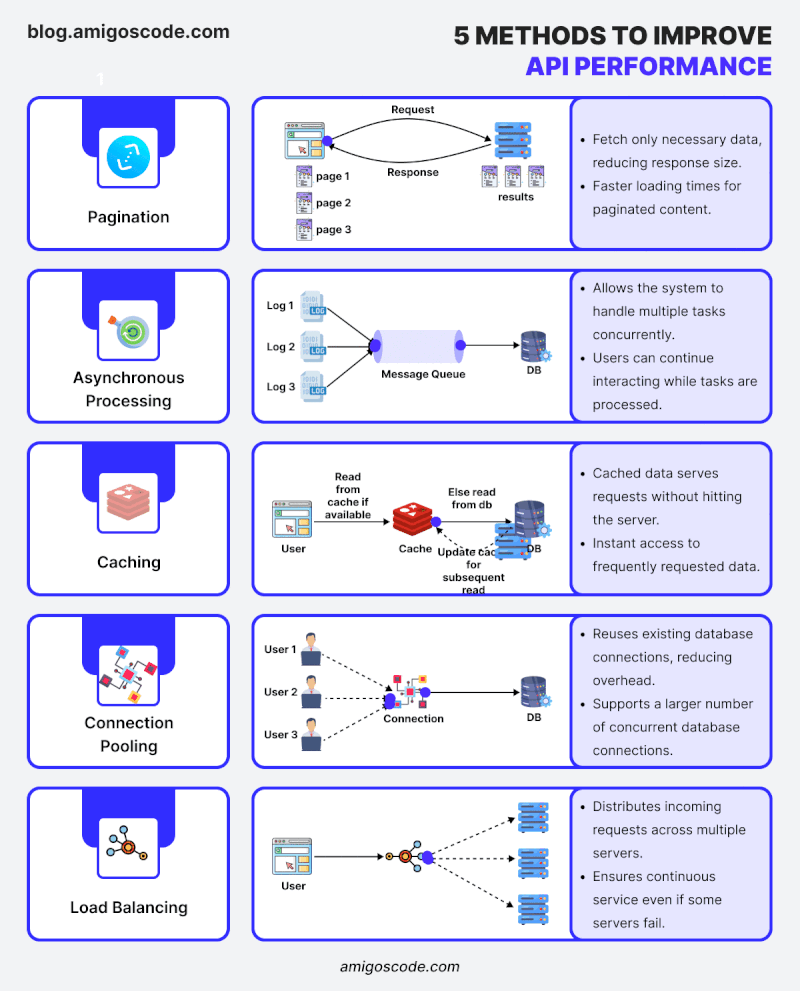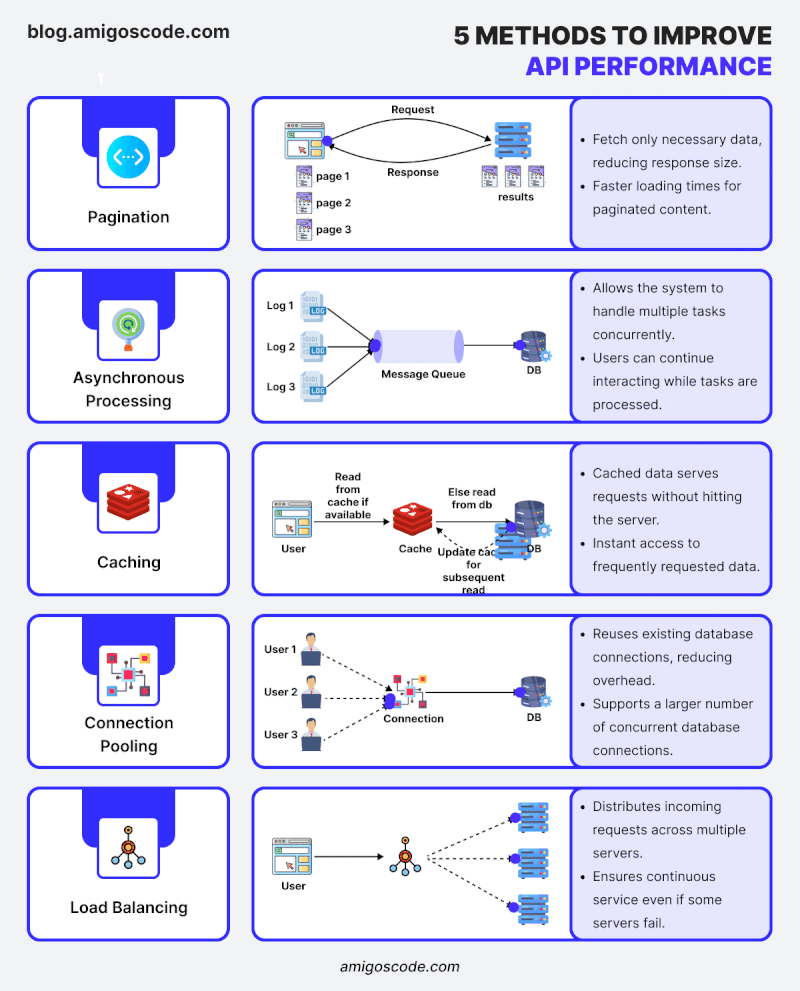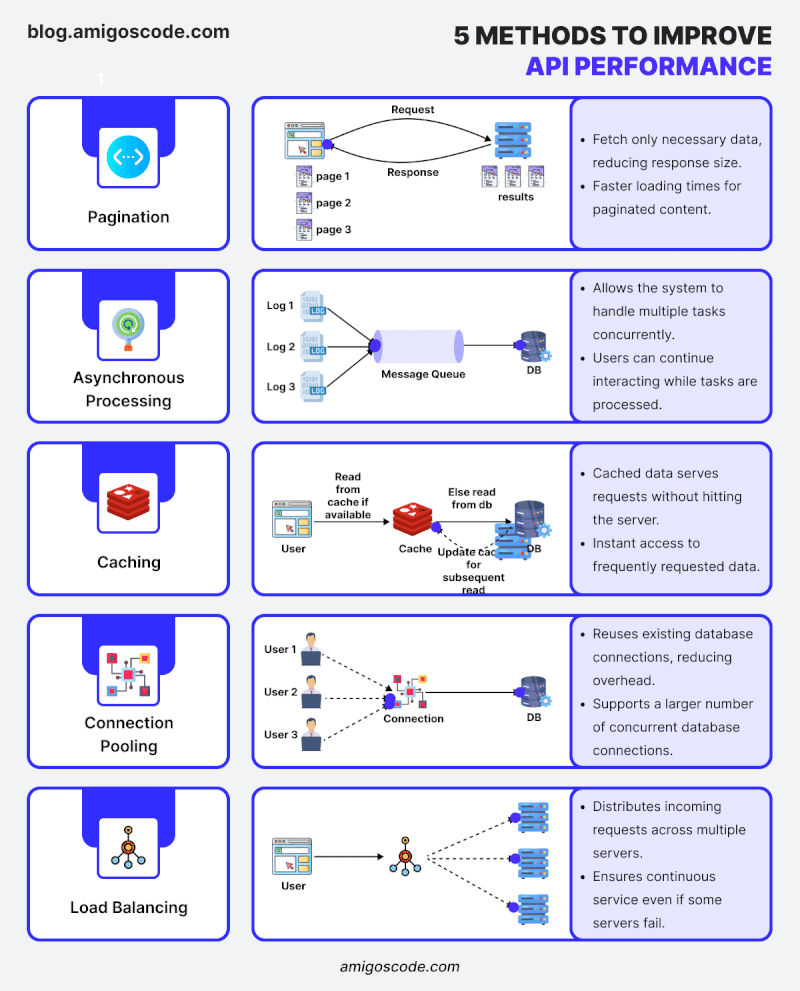
“Did you know that 80% of an application’s execution time is usually spent querying the database?” Optimizing the database is one of the most effective ways to speed up a Spring Boot application.
This article will guide you on how to design efficient queries, use caching and indexing to improve performance.
I will list common problems in programming in general and Java Spring Boot programming in particular, critical issues that make the application heavier and slower
1. Using for loops to call SQL queries
Problem
When processing data from a database in a Spring Boot application, a common mistake is using for loops to call SQL queries multiple times. This can lead to overloading the database and reducing the performance of the application. Here is an example and how to optimize it.
Suppose we have a list of userId and need to fetch the details of each user from the database. Here is the non-optimal way of using for loop to call SQL query:
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void fetchUserDetails(List<Integer> userIds) {
for (Integer userId : userIds) {
// SQL query is called repeatedly in each iteration of the for loop
var user = userRepository.findById(userId)
}
}
}
Problems with non-optimal example
- Poor performance: Each time the for loop is repeated, a new SQL query is executed, causing heavy load on the database and slowing down the application.
- Easy to cause overload errors: With a large list of userIds, the database can be overloaded and lead to connection errors or even application crashes.
Solution
Instead of executing the SQL query multiple times in the for loop, we can optimize by using a single query to get all the required data at once.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void fetchUserDetails(List<Integer> userIds) {
// Build a query with the list of userIds
var userLists = userRepository.findAllById(List.of(1,2,4,5,6));
}
}
Benefits of the optimized approach:
- Reduces the load on the database: Executes a single query for all userIds, minimizing the number of connections to the database and improving performance.
- Saves time: Reduces the overall execution time of the application because only one SQL query is executed instead of multiple queries.
- Easier maintenance: The source code is cleaner and easier to maintain because potential errors from repeating the query multiple times are avoided.
Conclusion
This guide will help you avoid common mistakes when using for loops to call SQL queries in Spring Boot and provide an optimized approach for your application.
2. Query loop N+1 when using Hibernate LAZY type = EAGER is not reasonable
Problem
When working with Hibernate in Spring Boot, one of the important concepts to understand is how to load related data (fetching) from the database. Hibernate supports two main types of data loading: LAZY and EAGER.
FetchType.LAZY(Lazy Loading): Related data is not loaded immediately when the main object is loaded. This data is loaded only when needed, saving memory and increasing performance when related data is not needed immediately.FetchType.EAGER(Immediate Loading): Related data is loaded immediately along with the main object, even if it may not be needed. This can lead to performance issues if the related data is large or unnecessary.
Example: Using FetchType.LAZY and FetchType.EAGER
Let’s say we have two entities (entities) in a student and course management application: Student and Course. A student can take multiple courses, creating a ManyToMany relationship between Student and Course.
//1. Define Entity `Student`
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
@Table(name="student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinColumn(
name = "course_id"
)
private Course course;
// Getters and Setters
}```
//fetch = FetchType.LAZY: The student's courses will only be loaded when accessing the courses property of the Student object.
// 2. Define Entity Course
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
@Table(name="course")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "courses", fetch = FetchType.EAGER)
private Set<Student> students = new HashSet<>();
// Getters and Setters
}
//fetch = FetchType.EAGER: Students who are enrolled in the course will be loaded immediately when the Course object is loaded.
Difference between FetchType.LAZY and FetchType.EAGER
FetchType.LAZY:
Benefits: Increase performance by not loading course data immediately.
Disadvantages: When accessing course data, there will be an additional query to the database.
FetchType.EAGER:
Benefits: Access related data (students) without additional queries.
Disadvantages: Loading all related data can cause poor performance if the data is too large or unnecessary, causing N+1 query.
Solution
To limit the N+1 query loop when using lazy type = EAGER, we will use lazy type = LAZY and group related objects to call the database once to get all data instead of using lazy type = EAGER
For example:
public class ClassServiceImpl{
private CourceRepository courceRepository;
private CoursetMapper coursetMapper;
private StudentRepository studentRepository;
private StudentMapper studentMapper;
public List<Course> fetchListStudent(){
// Get the Course list from the database.
var courseListEntity = courceRepository.findAll();
// Use DTO to convert data from entity to dto to return to end-user. [Why use DTO](https://viblo.asia/p/entity-domain-model-va-dto-sao-nhieu-qua-vay-YWOZroMPlQ0)
var courseListResponse = coursetMapper.toTarget(courseListEntity);
// Get a list of studentIds to query down to the database to get student data by course;
var studentIds = courseListResponse.getStudents().stream().map(s->s.getId()).collect(Collector.toSet()));
var studentLists = studentRepository.findAllByIds(studentIds);
var studentResponse = studentMapper.toTarget(studentLists);
var studentGroupByCourse = studentResponse.stream().map(f->studentMapper.toTarget(f)).collect(Collector.groupBy(f->f.getCource().getId())));
courseListResponse.forEach(f->){
if(studentGroupByCourse.containKey(f.getId()){
f.setStudents(studentGroupByCourse.get(f.getId));
}
}
return courseListResponse;
}
}
Using DTO, entity, and Map collection together to make data retrieval more convenient and easier to manipulate during the coding process and significantly increase performance compared to using lazy type = EAGER
Conclusion
Through the above example, you have understood how to fix when handling related objects in hibernate, grouping related objects to call down to the database to get data will be many times more optimal than using lazy type = EAGER.
Especially with applications with large traffic, millions, hundreds of millions of requests per day, optimization reduces 1 more query will save millions of other queries so be careful with what you write!
3. Handling Synchronization Inappropriately
Problem
Using synchronization in Java is necessary to ensure data consistency when multiple threads access and change the same resource. However, if not used appropriately, synchronization can cause many performance problems, including “thread contention” and “deadlock”.
Suppose we have an application that handles bank account transactions, with withdraw and deposit methods in the BankAccount class. To ensure data consistency, we use the synchronized keyword to synchronize all methods.
public class BankAccount {
private double balance;
public BankAccount(double initialBalance) {
this.balance = initialBalance;
}
// Synchronized method to synchronize withdrawal access
public synchronized void withdraw(double amount) {
if (balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount + ", New Balance: " + balance);
} else {
System.out.println("Insufficient balance");
}
}
// Synchronized method to synchronize deposit access
public synchronized void deposit(double amount) {
balance += amount;
System.out.println("Deposited: " + amount + ", New Balance: " + balance);
}
// Synchronized method to check balance
public synchronized double getBalance() {
return balance;
}
}
Problems with Invalid Example
- Too many synchronization locks: All methods of BankAccount are synchronized using the synchronized keyword. This causes the entire BankAccount object to be locked whenever a thread accesses one of these methods.
- Causes “thread contention”: Since all methods are locked, only one thread can access any method at a time. This causes long waits (increased wait time) when multiple threads need to access it simultaneously.
- Poor performance: Inappropriate synchronization slows down the performance of the application, especially when operations do not really need to be synchronized.
Solution
To optimize, we should only synchronize the code segments that are really needed instead of the entire method. In this case, we only need to synchronize access to the part that changes the balance variable. Or in general we will only use synchronization in adding/updating data where synchronization is required between threads, this ensures that transactions are consistent, avoiding conflicts in updating/adding data between multiple threads in a multiple threads environment.
public class BankAccount {
private double balance;
public BankAccount(double initialBalance) {
this.balance = initialBalance;
}
// Deposit method with synchronization only for the necessary part
public void withdraw(double amount) {
synchronized (this) {
if (balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount + ", New Balance: " + balance);
} else {
System.out.println("Insufficient balance");
}
}
// Deposit method with synchronization of only necessary parts
public void deposit(double amount) {
synchronized (this) {
balance += amount;
System.out.println("Deposited: " + amount + ", New Balance: " + balance);
}
}
// Balance check method does not need to be synchronized because it only reads data
public double getBalance() {
return balance;
}
}
Benefits of the Optimized Approach
- Reduced waiting time: By synchronizing only the necessary part of the code, we minimize locking the entire BankAccount object. This allows other threads to access unsynchronized methods (like getBalance) without waiting.
- Improved performance: Less synchronization improves the overall performance of the application because fewer threads are blocked.
- Avoid Thread Contention: By reducing the number of locks, we reduce the possibility of conflicts between threads when accessing shared resources.
Conclusion
Using synchronization appropriately is very important in multi-threaded programming. By synchronizing only the code that is really necessary, you can avoid performance issues and thread contention, ensuring that your application runs more smoothly and efficiently.
4. Inefficient Data Handling
Problem
In a Spring Boot application, inefficient data handling can lead to serious problems such as performance degradation, system resource consumption, and long response times. Here is an example that illustrates inefficient data handling and how to optimize it.
Suppose we have a Spring Boot application that needs to fetch all records from a large database table, and then apply some filtering and transformations to the data in Java code.
Suppose we have an Employee table with millions of records. Here is an inefficient way to fetch and handle all the data:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
@Service
public class EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
public List<EmployeeDTO> getFilteredEmployees() {
// Get all data from the database
List<Employee> employees = employeeRepository.findAll();
// Apply filters and transform data in Java code
return employees.stream()
.filter(emp -> emp.getAge() > 30) // Filter employees over 30 years old
.map(emp -> new EmployeeDTO(emp.getId(), emp.getName())) // Convert to DTO
.collect(Collectors.toList());
}
}
The problem here:
Get all data from the database: The findAll() method loads all data from the Employee table, which is inefficient when the table contains millions of records.
Data processing in Java code: Applying filters and transforming data in Java code instead of using optimized SQL queries, which leads to memory resource consumption and long processing time.
Causing “OutOfMemoryError” error: With large amounts of data, loading the entire data into memory can lead to “OutOfMemoryError” error.
Solution
Instead of loading the entire data and processing it in Java code, we should use custom queries with SQL or JPQL to get only the necessary data from the database.
//Repository
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository public interface EmployeeRepository extends JpaRepository<Employee, Long> { // Use JPQL to get only the necessary data @Query("SELECT new com.example.EmployeeDTO(e.id, e.name) FROM Employee e WHERE e.age > 30") List<EmployeeDTO> findEmployeesAboveAge30();
} //Service import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service public class EmployeeService { @Autowired private EmployeeRepository employeeRepository;
public List<EmployeeDTO> getFilteredEmployees() {
// Get the required data from the database using an optimized query
return employeeRepository.findEmployeesAboveAge30();
}
}
Benefits of this Approach:
Reduced load on the database: Only fetch the required data from the database, minimizing the amount of data loaded into memory.
Higher performance: Applying filters and transformations to the database instead of in the Java code, improves response time and resource efficiency.
Avoiding “OutOfMemoryError” errors: By limiting the amount of data loaded into memory, the risk of encountering “OutOfMemoryError” errors is reduced.
Conclusion
Optimal data handling in Spring Boot applications is crucial to ensure application performance and stability. Using custom queries to fetch only the required data from the database is one of the best methods to achieve this.
5. Inefficient Memory Management
Problem
Inefficient memory management in a Spring Boot application can lead to problems such as memory consumption, performance degradation, or even an “OutOfMemoryError”. Here is an example of inefficient memory management and how to optimize it to improve performance.
Suppose we have a Spring Boot application that needs to process a list of users and store the results in memory for further processing. However, instead of using efficient data structures or proper memory management techniques, the application uses a suboptimal approach.
Suppose we have a processUsers() method in a UserService class that processes a list of users and stores the results in a global List.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
// Global list to store processed users
private List<User> processedUsers = new ArrayList<>();
public void processUsers() {
// Get all users from the database
List<User> users = userRepository.findAll();
// Process each user and add to the global list
for (User user : users) {
// Assume some memory intensive processing
processUser(user);
processedUsers.add(user);
}
}
private void processUser(User user) {
// Complex memory intensive processing
user.setName(user.getName().toUpperCase());
}
}
Suboptimal issues:
- Long-term Data Storage in Memory: Using a global List (processedUsers) to store processed data without a strategy for deleting or cleaning up memory.
- Unnecessary Memory Consumption: All processed User objects are kept in memory, leading to unnecessary memory consumption when the number of users is large.
- Risk of “OutOfMemoryError” Error: When the processedUsers list is too large, the application may encounter an “OutOfMemoryError” error.
Solution
Instead of storing all processed data in memory, we can use a more efficient approach, such as storing only the necessary data, using temporary memory, or batch processing.
- Solution using Batch Processing and Temporary Storage
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void processUsers() {
// Get all users from the database in small batches
int batchSize = 100;
int start = 0;
while (true) {
// Get a batch of users
List<User> users = userRepository.findUsersWithPagination(start, batchSize);
if (users.isEmpty()) {
break;
}
// Process each user in the batch
for (User user : users) {
processUser(user);
// Do not store users in long-term memory
}
start += batchSize;
}
}
private void processUser(User user) {
// Complex processing consumes a lot of memory
user.setName(user.getName().toUpperCase());
}
}
- Repository with Pagination Query
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT u FROM User u ORDER BY u.id ASC")
List<User> findUsersWithPagination(@Param("start") int start, @Param("batchSize") int batchSize);
}
Benefits of the Optimized Approach
Reduce Memory Consumption: Processing data in small batches reduces the memory required for each processing.
Improve Performance: By offloading long-term data storage into memory, the application can process faster and consume less resources.
Avoid “OutOfMemoryError”: Proper memory management avoids “OutOfMemoryError” errors when processing large data.
Conclusion
Effective memory management is an important part of Spring Boot application development. Using techniques like batch processing, storing only the data needed, and cleaning memory promptly can help improve application performance and stability.
6. Using Connection Pool Size
Problem
In Spring Boot applications, using a Connection Pool is important for efficient management of database connections. A Connection Pool is configured with a specific size (pool size) to determine the number of concurrent connections that can be opened to the database. Incorrectly configuring the Connection Pool size can lead to problems such as connection congestion, performance degradation, or inefficient resource utilization.
Solution
Why is Connection Pool Size Important?
- Resource Optimization: Helps optimize system resources by reusing database connections.
- Reduce Connection Creation Cost: Opening a connection to a database is time-consuming and resource-intensive; using a Connection Pool helps reduce this cost.
- Improved Performance: Helps improve application performance when handling multiple concurrent requests by maintaining a stable number of connections.
Here is an example of how to configure Connection Pool Size for a Spring Boot application using HikariCP — Spring Boot’s default Connection Pool.
- Configuration in
application.propertiesYou can configure the Connection Pool size by adding the following properties to theapplication.propertiesfile:
# Configure database connection
spring.datasource.url=jdbc:mysql://localhost:3306/mydatabase
spring.datasource.username=myuser
spring.datasource.password=mypassword
# Configure HikariCP Connection Pool
spring.datasource.hikari.maximum-pool-size=10
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.max-lifetime=1800000
spring.datasource.hikari.connection-timeout=20000
2. Configuration in `application.yml`
``yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydatabase
username: myuser
password: mypassword
hikari:
maximum-pool-size: 10
minimum-idle: 5
idle-timeout: 30000
max-lifetime: 1800000
connection-timeout: 20000
Conclusion
Correctly configuring the Connection Pool Size in Spring Boot is very important to ensure high performance and efficient use of system resources. HikariCP, the default Connection Pool of Spring Boot, provides flexible configuration options to manage connections to the database in an optimal way.
Benefits of Proper Connection Pool Configuration
- Improve Application Speed: Reduce connection time and reuse connections efficiently.
- Optimize Resources: Help save system resources and avoid errors due to connection overload.
- Ensure Stability: Minimize the risk of connections timed out or being rejected due to overload.
Make sure you choose the right Connection Pool size for your needs and system architecture to optimize application performance and stability.
7. Use Distributed Database
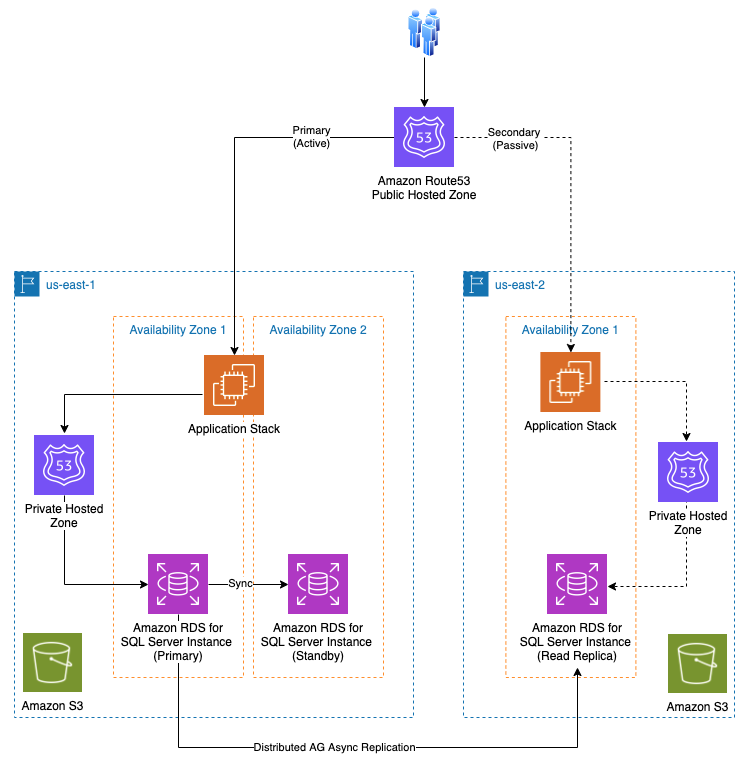
Problem
In large-scale applications, using a distributed database with dedicated endpoints for reading and writing data improves performance, reliability, and scalability. This model typically consists of a master database for writing data and multiple replica databases for reading data.
Solution
Why use Read/Write Endpoints in Distributed Databases?
- Improved Performance: Splitting read and write traffic reduces the load on the master database, improving overall performance.
- Increased Reliability: Using replicas for reading data reduces the risk of data loss and increases resilience.
- Scalability: Easily scale the system by adding more replicas to serve read requests.
Conclusion
Using read/write endpoints in distributed databases helps improve performance and optimize resources of Spring Boot applications. By using techniques such as DataSource classification, AOP, and DataSource context management, we can easily manage read/write connections effectively.
Summary
In this tutorial, I have guided you through 6 classic ways to optimize spring boot applications. This is all that I have applied in the project during the performance optimization process for Core Java Spring Boot Application. In the context of increasingly complex web applications, optimizing application performance is an indispensable requirement. The article has focused on common bottlenecks in Spring Boot applications and provided specific solutions. However, optimization also involves many other factors such as database, network, and hardware. In the future, with the development of new technologies, we can expect to have more effective optimization tools and methods.